クライアント様や社内のチームでタスクを共有するためにBacklogを利用している人は多いのではないでしょうか。
私もBacklogを使用しており大変良いツールだと思いますが、少し惜しいと感じる点があります。
それは工数(予定時間・実績時間)の集計ができない点です。
各課題には
- 予想される工数を記入する「予定時間」欄
- 実際の工数を記入する「実績時間」欄
がありますが、その集計をBacklog上で確認することはできません。
近い機能としてバーンダウンチャートがありますが、この機能は目的が異なるので集計を確認することには適していません。
工数を集計するには、課題一覧をCSVなどで書き出してExcelなどの表計算ソフトで集計するか、課題一覧ページを表示して暗算や手計算するしかありません。
しかし、どちらの方法も頻繁に行うには面倒です。
そこで本記事ではBacklogの工数をGoogleスプレッドシートで自動的に集計する方法をご紹介します。
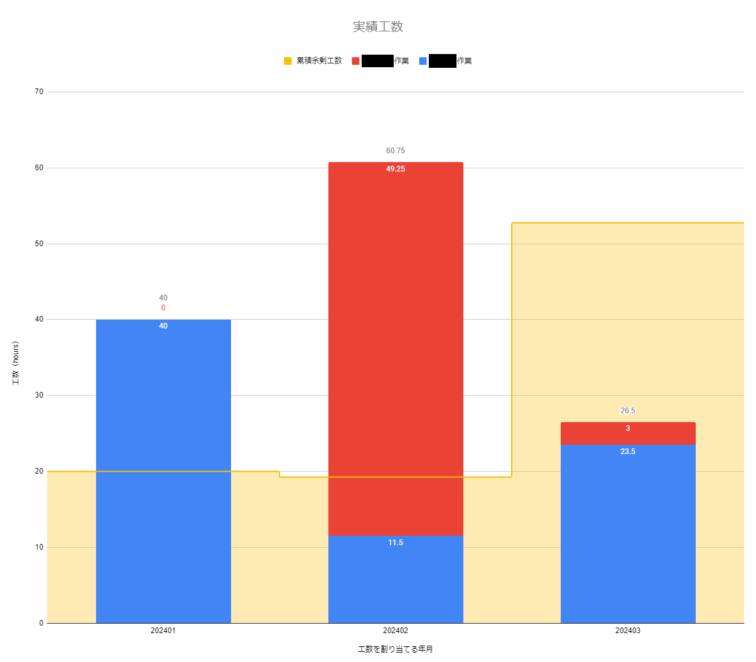
Backlogの工数をGoogleスプレッドシートで自動的に集計した結果
Backlogからデータ取得をするApps Scriptと、取得したBacklogのデータから工数を集計する関数を組み合わせることで、下記のような表とグラフで工数を集計することができます。
作成したスプレッドシートのポイント
- Backlogからのデータ取得頻度は任意に設定可能(例:1分ごと、1日ごと)
- Backlogからのデータ取得はプロジェクト単位(複数のプロジェクトを横断しての集計は不可)
- 集計表にはピボットテーブルを使用していないため、表を自由に加工しやすい

スプレッドシートの実装方法
初めに、スプレッドシートを実装する上での前提をお話しします。
次にスプレッドシートの実装手順を説明します。
そして最後にスプレッドシートについて少し補足します。
【前提】Backlogの使用方法について
私は以下のようにBacklogの各項目を使用しています。
- カテゴリー:工数を負担する会社やチームを設定(例:A社の作業、チームBの作業)
- マイルストーン:工数を割り当てる年月を設定(例:2024年3月分の工数としたい→”202403″と設定)
- 予定時間:タスクを完了するために予想される工数(hours)を設定
- 実績時間:タスクを完了するために実際にかかった工数(hours)を設定
Backlogではカテゴリーとマイルストーン(と発生バージョン)を複数選択することもできますが、私は単一選択のみで使用しています。
そのため今回は課題1つにつき、カテゴリーとマイルストーン(と発生バージョン)はそれぞれ1つのみ設定されていることを前提にスプレッドシートを作成してあります。(2つ以上設定している場合、その内の1つが取得されます)
スプレッドシートの実装手順
- こちらのスプレッドシートをご自分のGoogleドライブにコピーしてください。
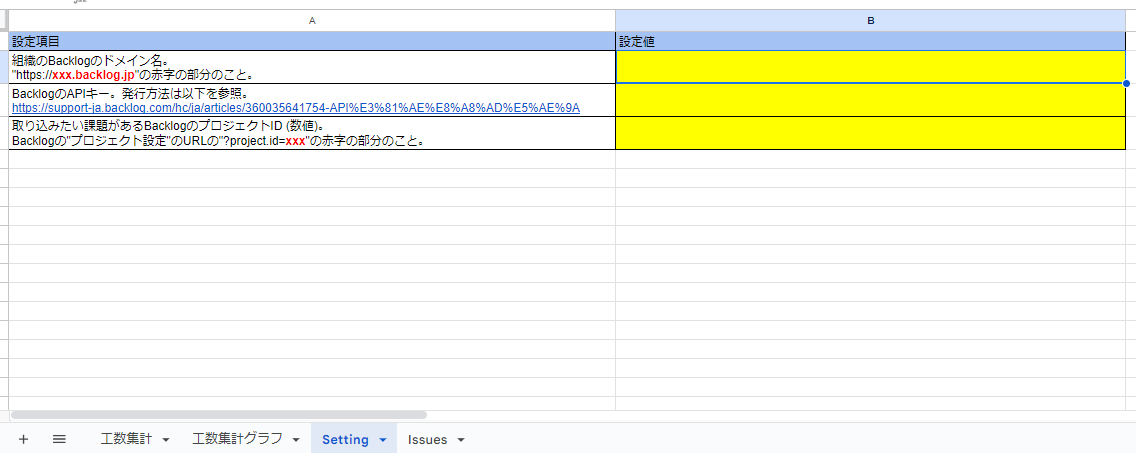
- 「Setting」シートの黄色セルに値を入力してください。
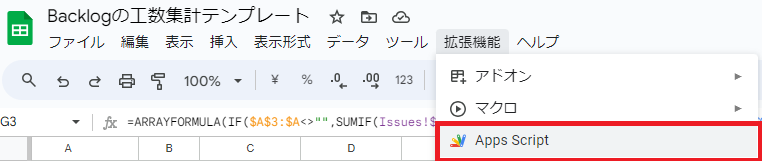
- メニューバー > 拡張機能 > Apps Script を開いてください。
- “dump_backlog_issues.gs”が開かれた状態になるかと思うので、メニューバーにある「実行」ボタンを押してください。
権限の許可が求められた場合は承認してください。
「Issues」シートに課題一覧が表示されていればBacklogからのデータ取得は成功です。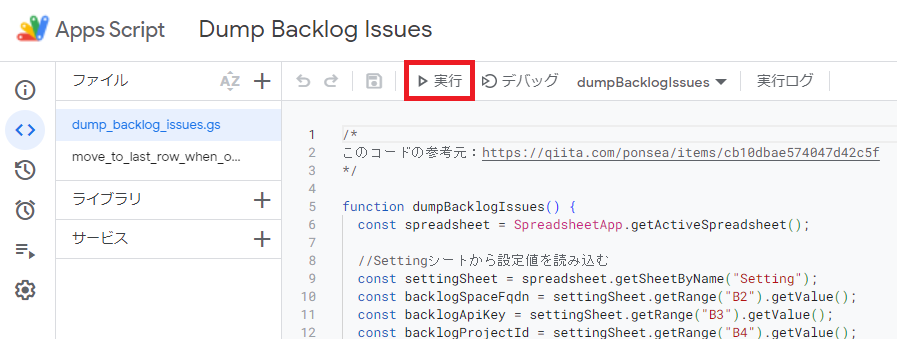
- データ取得が成功したら定期的にデータを更新するように設定します。
左のサイドメニューから「トリガー」を開き、右下の「+トリガーを追加」ボタンを押してください。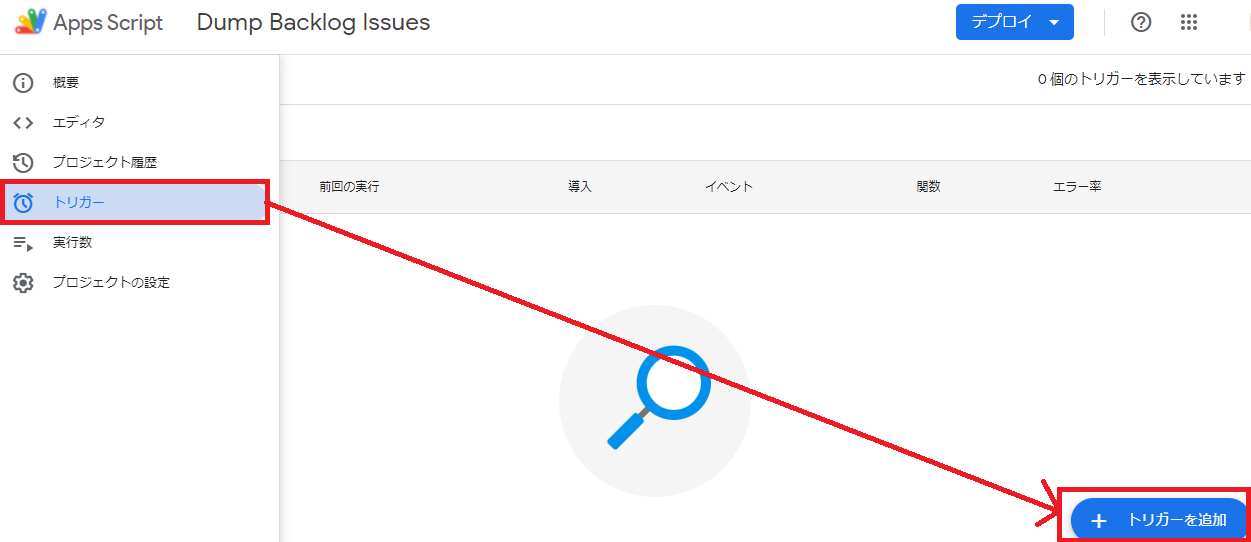
- 設定画面が出てきますので、赤枠部を任意の設定にし、右下の「保存」ボタンを押してください。
下記は5分おきにデータを更新する場合の設定例です。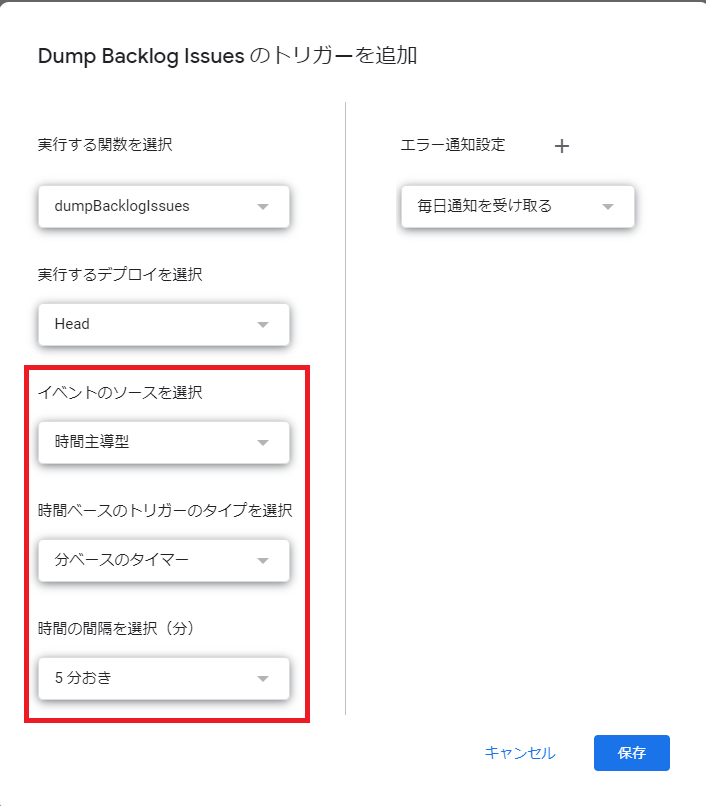
- 「工数集計」シートの以下の項目をご自分の状況により調整してください。
- 規定工数(B3)の定数
下記関数の60と書いてある箇所です。
=ARRAYFORMULA(IF($A$3:$A<>””,60,””))
ここで設定した値が余剰工数(F, J列)を計算する際の基準値として使用されます。 - 「カテゴリー1(C2)」「カテゴリー2(D2)」の名称
Backlogで使用しているカテゴリー名を設定してください。
例えばカテゴリーとして「A社」と「B社」があれば、C2に「A社」、D2に「B社」と入力してください。
カテゴリーが3つ以上ある場合は列を適宜追加してください。
ここで設定したカテゴリー名で課題がフィルタリングされ、当該の列で集計されます。
- 規定工数(B3)の定数
【補足】Apps Scriptについて
Backlogからデータ取得をするApps Scriptはこちらの記事を参考に、少し改造させていただきました。
Backlogから取得する項目は以下です。
| Backlogの項目名 | 「Issues」シートの項目名 |
| 種別 | issueType.name |
| キー | issueKey |
| 件名 | summary |
| 担当者 | assignee.name |
| 状態 | status.name |
| カテゴリー | category.0.name |
| 優先度 | priority.name |
| 発生バージョン | version.0.name |
| マイルストーン | milestone.0.name |
| 登録日 | created |
| 更新日 | updated |
| 開始日 | startDate |
| 期限日 | dueDate |
| 予定時間 | estimatedHours |
| 実績時間 | actualHours |
| 登録者 | createdUser.name |
「Issues」シートはデータを更新するたびに初期化されます。
また「工数集計」シートで「Issues」シートを参照しているため、「Issues」シートはユーザー側で編集しないことを推奨します。
「工数集計」シートの行数が増えてくると1番下の行までスクロールすることが面倒になります。
そこでスプレッドシートを開いた際、A列の1番下の行までスクロールするApps Script “move_to_last_row_when_open.gs”を実装しています。
この機能が不要な場合は”move_to_last_row_when_open.gs”ごと削除してください。
【補足】「工数集計」シートについて
行はA列の昇順です。
A列には工数を割り当てる年月(例:202402, 202403)が入るため、新しい日付が下に来る並び順となります。
A3の下記関数のtrueをfalseにすることで降順にできますが、K列(累積余剰工数)の値が狂いますのでご注意ください。
=SORT(UNIQUE(FILTER(Issues!I2:I,Issues!I2:I<>””)),1,true)
B~K列はすべてARRAYFORMULA関数を使用しています。
この関数を使用することで行数が増えた場合でも手動で関数をコピー&ペーストしたり、オートフィルしたりすることなく、自動的にすべての行に関数が適用されます。
最後に
「工数集計」シートと似たようなことは、ピボットテーブルを使うことでも実現できます。
手軽に集計したい場合はピボットテーブルのほうが簡単です。
しかし、ピボットテーブルでは表内に任意の列を追加するなどの2次加工がしにくいです。
そのような場合は、今回のように自分で疑似ピボットテーブルを作成すると良いと思います。

株式会社GLASS コンサルタント。2017年に大手電子部品メーカーに入社。設計部門で製品設計に携わる。2018年に品質保証部門に異動し、主に製品不具合の分析を担当。2023年にマーケティング部門に異動し、会社ホームページの分析と改善に従事。プログラミングスキルとWebサイト制作・管理の経験を生かし、分析用ダッシュボードの作成やUI(ユーザーインターフェース)の改善に貢献。2024年に株式会社GLASSに入社。

